








本文来自微信公众号 “策略产品研究院”,作者:一颗西兰花,纷传经授权发布。
推荐系统中包含着许多模块,数据流是其中的一个重要模块。
在上篇文章里,作者阐述了推荐策略产品中的系统框架及模块演进;本篇文章里,作者总结了推荐系统框架中的数据流模块,让我们一起来看一下。
在本章节,我们来了解推荐系统框架的数据流。
01
概括
为什么要了解数据流?
对于一款非常复杂的产品,比如像推荐系统这块由多个模块组成的产品,只有了解了其数据流,才能知道这个系统是如何运作的。
对于产品经理自身而言,只有了解了整体数据流,才能增强自己对复杂产品设计的把控能力。
02
推荐系统数据流
1.背景Brief
要了解推荐系统的数据流,首先需要知道,对于一个推荐系统,主要的数据模块。可以将其抽象成3个模块:用户数据、物料数据、用户行为。
2. 推荐系统目标
对于一个推荐系统,它的目标是什么?通过两个case来了解。
1)Case 1:资讯场景
比如资讯场景业务目标是点击率。点击率的计算逻辑 = click / show。
那为了提升点击率,我们需要哪些数据实现目标?
静态数据:用户表、物料表。
用户行为数据:用户行为数据。
聚焦到用户行为数据,如何定义哪些是正样本、哪些是负样本。

需要注意的是,在行为数据定义时候(样本定义时候),经常出现的几个show虚报的问题:
推荐结果即show。推荐结果即show的意思是,比如一个相关推荐场景,后台服务器一次给出的预测结果是10条数据,客户端只展现了4条。
为了图方便,客户的上报show的逻辑是将所有的返回推荐结果都上报为show。
加载即show。在信息流场景,往往需要预加载。但是很多预加载的item,实际上尚未被展示。
客户的埋点逻辑是加载即上报show,因此会导致show虚高。
信息流上下滑动。在信息流场景,还经常出现的一个问题是,用户经常上下刷动,所以同一物料会有多次曝光,建议上报时候做去重设置。
2)Case 2:小视频场景
比如小视频场景,建模目标是完播率,即视频的播放时长/视频的总时长。
3. 推荐系统如何实现业务目标
将推荐系统实现业务目标拆分成两条数据流来理解,在线数据流和离线数据流。
1)在线数据流
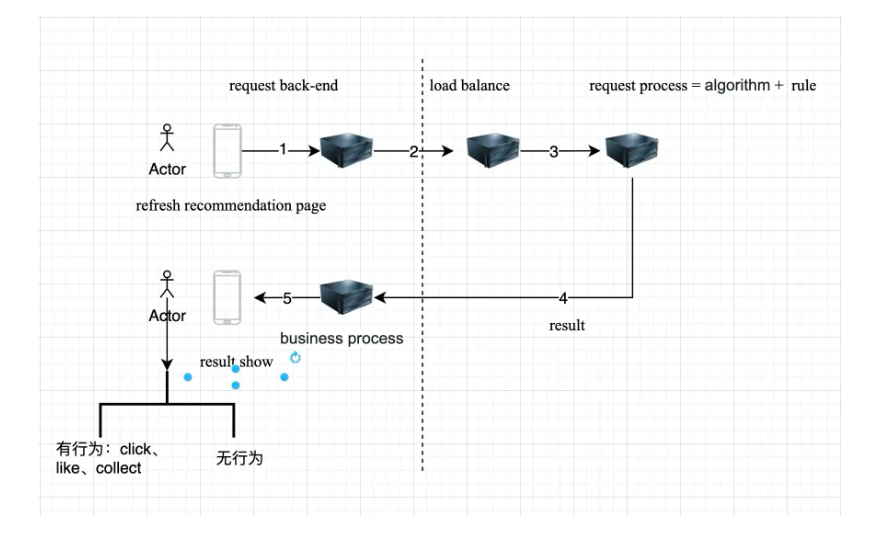
在线数据流是指一个请求进入到推荐系统到给出预估结果的流程,参考下述示例图。
接着进一步了解在线数据流。
用户来到APP,打开APP,这个时候前端会像服务器后端发送请求,接着服务器后端会像推荐系统(SaaS服务)发送请求。
推荐服务接受到这个请求,会先进行load balance,接着后端处理,在后端处理分为算法和规则,算法即召回和排序,规则即rerank。
根据2.2的描述,我们知道,对于一个推荐系统来说,都有其特定的目标,当我们完成目标确认后,比如提升点击率或者完播率。
接着就可以开始建模了。假设模型已经ready。来看一下推荐系统的在线流程~
召回(Recall):召回的作用是从整个物料库中,通过某一种/多种策略,快速召回一小批物料,供后续模型打分使用。
排序(Rank):排序是将前一个阶段召回的物料进行模型排序。
重排(Rerank)
重排是什么?
重排是基于排序环节的打分结果,对上述结果再次进行排序。
为什么需要重排?
在上一个环节,排序做的事本质上是预测用户对物品该兴趣的概率,考虑的只是物品与用户之间的关系,但是忽略掉了物品之间的相关性。
如何理解呢?分享一个极端的case,小红最近酷爱刷电影剪辑类小视频,模型学习的话,很可能学出来最后给用户推荐的都是同一个publisher的10条item。
这样肯定是不行的,试想,如果你正在刷抖音,连续10条都给你推荐同一个博主的内容,这个体验能好吗?所以需要rerank。
重排环节一般会做什么?
重排阶段是个策略出没之地,就是集中了各种业务和技术策略。
比如为了更好的推荐体验,这里会加入去除重复、结果打散增加推荐结果的多样性、强插某种类型的推荐结果等等不同类型的策略。
2)离线
什么是离线数据流呢?模型训练以及模型的更新都是离线数据流完成的事。
离线模型的训练以及模型的更新,涉及到多个数据模块的配合,包括用户画像、物料画像、行为日志,离线数据流,我们下章节见~




