






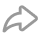


本文来自微信公众号 ”旅行顺便改变世界“,作者: Ver0,纷传经授权发布。
本篇大量吐槽管饱请谨慎服用。
最近还看了一本书,上面提到有啥想做又有困难的事,就把顾虑的点写下来。很多时候写下来就会觉得心中的矛盾不攻自破。很有道理,其实思考的时候也是如此,如果单是看,我可能以为自己都懂了,说又可能说不出十分之一,但是写下来,就可以问问自己,这些道理,真的明白了吗?
就算真的明白了,是否能够跟其他人说明白呢?
上回我们刚聊完了埋点,接下来就要继续说说,数据已经取回来了,要怎么后续应用让数据发挥更大的价值。
就像唐僧取了经,总不至于搬回大唐就完了,还得看看如何弘扬佛法。

01
数据标签 & 用户画像
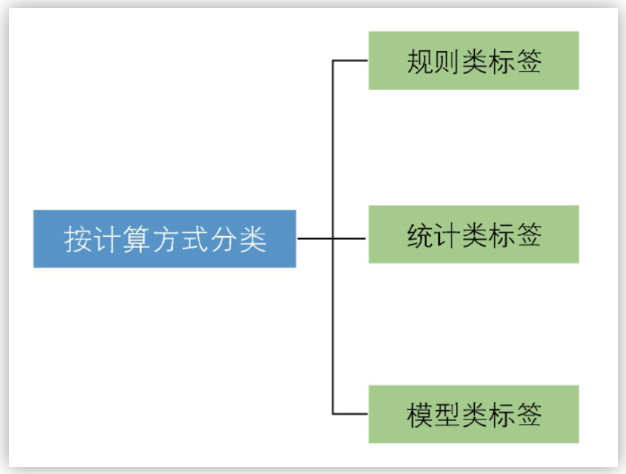
而其中有一种较为合理的应用形式就是构建用户标签体系,以丰富用户画像,其具体实践为:「依据用户历史行为数据对每个用户的社会属性、商业属性、内容属性、行为属性等打上相应的标签,以实现用户分层精准运营。」
这些用户标签大体又可以分为三类,「规则类标签」,「统计类标签」和「模型类标签」。
「规则类标签」比较好理解,我们可以通过业务经验 & 运营同学沟通按特定的规则为用户打标,比如我确定体验了三类内容的用户为高意向付费用户,我们就可以生成一个标签判定该用户是否为体验过三类内容的用户。
「统计类标签」则是对某些常用维度的数据做统计,比如用户最后一次活跃时间,用户平均活跃时长等。
这两种标签的好处是理解起来较为容易,解释成本也比较低。
相对而言,模型类标签则则比较偏黑盒了,可能是算法工程师通过各种机器学习结合多种用户特征做出测算得到的结果,最终得到的结果可能类似「高付费意向用户」和「高流失可能用户」,对于这类标签,我们通常用就完事了。
我个人看来,好的用户标签不一定是大而全的,毕竟维护一整套标签成本也是相当高的。好的标签应该从业务中提炼并具有可操作性,另外最好有一定的区分度(举个栗子,总不能90%的用户都是高付费意向用户吧,这样想要分群运营是很不方便的),便于业务方去灵活使用。
一个优秀的标签设计可以为人群圈选和自动化提供比较大的便利度,也为之后的指标体系构建打下了良好的基础。而对于分析师自己来说,好的标签也可以省掉一大段case when的时间。
02
数据指标体系
这块,可以说是「方法论」的重灾区了。本来就是偏向于业务的事情,偏生每个业务又都长得这么五花八门,其实是很难总结出一套灵丹妙药的。
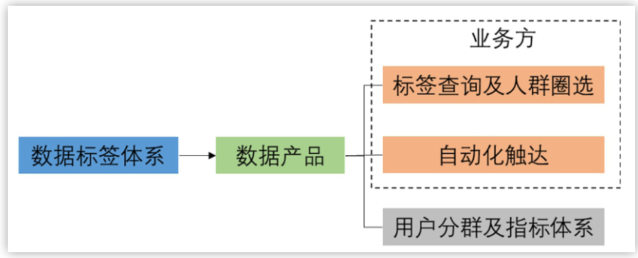
要说有没有方法论,也有,不但有,还挺多。像作者就提到了n个可以着手的模型,并梳理了他们之间的关系:OSM(Object Strategy Measure)、AARRR(Acquisition Activation Retention Revenue Referral)、UJM(User Journey Map),MECE(Mutually Exclusive Collectively Exhaustive)。
但到了具体实操环节,我不建议迷信任何一种方法论,而是最好找准一个业务目标,然后根据这个业务目标事无巨细的从多个角度,从各个维度和环节去对业务做拆解。
作者说的几个模型的确都是不错的着手点。比如AARRR模型就是让我们从一个产品的全生命周期去了解有哪些指标值得进一步细拆,人货场模型则是让我们又关注到商品层面和店铺层面有哪些关键指标需要留意。
我们可以通过了解很多「模型」获得很多理想的切入点,并进一步抽象。业务关心哪些指标,我们就从哪些指标出发,一切都需要回到商业模式中去。
但是模型是标准化的,业务则不是。所以最开始并不追求尽善尽美,多进行几次异动分析,沉淀出经验就可以了解从哪些角度去做细化了。一个好的指标体系的搭建往往不是一蹴而就的,很多时候我们都是从日常分析中去提炼总结,然后不断丰富和完善我们的数据指标体系。
早期写过一篇搭指标体系的基本思路和注意事项,现在看来稍显稚嫩。
03
对比思维
从这章开始,进入了各种python代码和公式环节。我也开始只做重点的梳理,作为日后复习的提纲。
分析其实就是无休无止的对比,对比的方式和对象是多种多样的,其实我们只需要小心一个点,我们对比的对象是否具有可比性。对比的对象必须是相似的,比如说打游戏总不能对比辅助和输出的杀人数据,你是莫伊拉当我没说(莫伊拉:?)。
另外一点是对比的指标计算方式得是一致的。你可别笑,这个在业务里很常见,很多指标明明是一个名字,业务上统计的方式却全然不同。比如一个简单的完播率,有时候起点是启动,有时候起点是浏览详情页,有时候起点是播放,怎么可能拿来做比较呢。所以分析师在提供数据时最好不要惯性思维,先聊清楚指标的口径是怎么样的,是否符合常理中大家一贯的认知。
而后作者用不少篇幅讲了ab测。其实还是比较浅,毕竟讲深了那可就是几本书,这部分建议参考更多专业领域书籍。其中有些内容甚至是有待商榷的,比如作者说,「假设高频用户每天都登录,中频用户每周至少登录一次,而低频用户每个月至少登录一次,如果加大流量分配,3天完成A/B试验显然是不科学的,因为所选的用户只覆盖了高频用户,而忽略了中频和低频用户。」
这其实有点没说清楚道理。实验每天都是抽样部分用户,活跃用户中低频用户占比都是固定,哪怕拉长周期,低频用户占比仍然是较低的,我们要是嫌样本低,可能要分人群去看效果。要是嫌低频用户没进来,那更不对头,毕竟再低频,也总有些低频用户恰好在你实验的日子来了不是~
实验周期拉长,其实是要覆盖至少一个产品活跃周期,防止比如三天都落在工作日了,就把只在周末有空来的用户拉下了。
这里重点mark多重比较的场景下,想要避免误报调整显著性水平的方法:Bonferroni法、holm's step down法、Hochberg standby法。
关于AB测推荐极客时间一个小课:《A/B 测试从0到1》。
04
分群思维
分群思维方面,作者主要介绍了四种方法:结构分析,同期群分析,RFM模型和K-Means。
结构分析可以理解为MECE的各种应用,即按照各类业务含义把用户分类打标,比如游戏里的大R,中R,小R和无氪。
同期群听着高大上其实就是我们通常了解到的留存分析。这个留存未必是用户的活跃行为也可以是各类常见行为的留存,通过留存分析,我们可以找到用户行为规律和拐点找到合适的干涉点,同时也可以对类似的用户未来的行为做适当预测。比如上周某渠道的用户7日留存率大约是30%,那么本周可能也类似,我们既可以通过历史用户的留存率去预测未来的活跃情况,也可以通过和优质人群的对比去判断我们新选择的渠道拉来的用户质量如何。
至于RFM,因为好理解总被各种培训班拿去教大家数据分析,资料一搜有一筐这么多,老生常谈,就不多说了。
K-Means方面作者提到了选择K值的几种方法:卡琳斯基-哈拉巴斯指数,轮廓系数和簇内平方和,并分别进行了代码实现。有需要的同学可以进一步进行学习。
另外作者在代码中演示了多指标进行归一化消除特征差异的处理步骤(对数据进行log(x+1)变换,缩小各项指标的区间范围,其次通过Z-Score变换将特征值映射到N(0,1)的正态分布),以及归一化数据如何映射到未归一化数据(方便业务理解)。可供有需要的小伙伴参考。
05
相关思维
这一章作者首先介绍了相关性和热力图的代码实现。而后重点介绍了因果推断,值得重点学习。
遗憾的是每一个部分都讲的比较浅尝辄止,更适合当做一个大框架来了解,这块内容估计要等我的统计修行到一定程度并学习大量因果推论以后再来补充了。
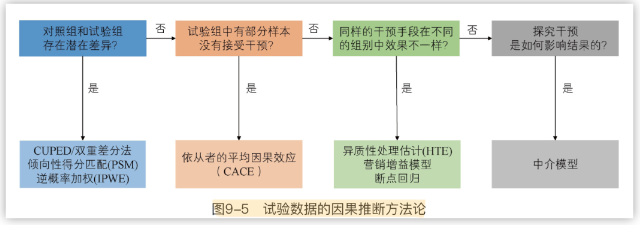
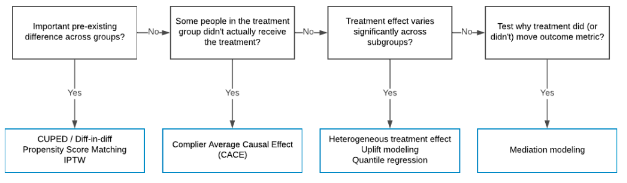
BTW,查资料时也了解到这张图和这章很多内容都是基于Uber团队2009年分享的如何用因果推断提升用户体验,作者稍显不太厚道的直接拿了原版的ref(高情商:作者为汉化事业做出了杰出的贡献;低情商:这多么像写论文的我啊……),懂的自然懂。方便查资料贴个英文版的原文(这个博客还在持续更新,值得后续学习),写得更为详细:
https://www.uber.com/en-HK/blog/causal-inference-at-uber/
另外也补充一句原文有说作者没说的话:这个框架没有很详尽主要是Uber实践中一小部分的总结,所以实际用啥不用啥,估计还得大佬们研究。
作者的ref(换个ref格式安能辨我是雄雌,另外我作为一枚学渣的ref经验告诉我,正经ref,姓一般是写全称的,名字写缩写,Joann P,Joshua D这种写法作者最好注意下):

原文的ref:

总之,学因果推荐,还是回到经济中去学吧,反正我还是打算先买书了(…就是咱被ref的Angrist JD,2021年诺贝尔经济学奖得主的力作:《精通计量》)…具体实现就看各种大佬写的python脚本了。




