








本文来自微信公众号 ”旅行顺便改变世界“,作者: Ver0,纷传经授权发布。
裸辞后上个月开始找工作啦,昨天刚得知,某个颇为倾心的工作终面后等了一周,还是不了了之了。原因此刻也不想深究了,可能是老天认为这份工作不适合我,又或者是觉得我的道行还不够。市场大环境顺流而下,我也未能成为逆流者~
停下来审视自己的一切,也决定趁这个机会补补课了,比如一直比较薄弱又没太多机会在工作中实操的python,统计 & 算法模型的运用场景横竖得懂点儿(基础课不好好学欠下的债,果然还是得还的)。现在算是难得有动力也有时间学习的空档期,应该好好珍惜。

当然,这也是事后冷静下来才会说的漂亮话。
昨天其实挺down的,可能是过往的一切过于顺利,习惯稍稍努力就有回报的生活。现在想想,眼前的挫折也没什么大不了,和朋友聊天,提到人生几十年,放眼历史可能是弹指一瞬间,几年的贬谪,在书上就是一句话,这几个月在我的人生里又只是一瞬间罢了,所以打算同时再多看点历史书,感受自己的渺小(同期也在看《羊道》系列,在自然面前,人类又是何其渺小的生物,大自然却是很宽容的)。
其实用上帝视角看自己,就会变得客观许多,也不再容易被情绪牵制。
但如果情绪真的上头了,也别太苛责自己,大吃一顿,睡一觉一定会觉得没什么大不了。生活很美好,不必透支焦躁。

感谢我还是那个我,讨厌消耗,不愿意停止前行的脚步,愿我们「十年饮冰,热血依旧」。今时往日所有的努力都会化成选择的底气。
我会给自己更多耐心,也希望家人们能给我更多耐心吧。
也感谢支持我的人,你们的鼓励对我来说意义重大。
闲话说到这里,聊聊这本书:《数据分析之道:用数据思维指导业务业务实战》。
首先结合个人的理解整理这本书的干货,而后再来说,为什么我说不要痴迷于方法论(其实和这本书关系不大,不过是个人一些牢骚话罢了~)。
请记住,没被提到的部分并不代表不重要,只是我可能了然于心,不觉得需要额外记下罢了。个人理解可能有偏颇,全当交流。
那么,干货又有哪些呢?
01
数据治理流程
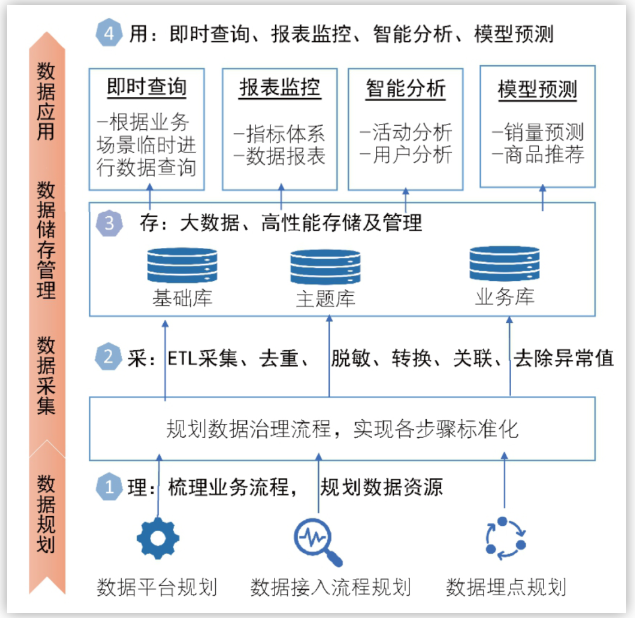
第一章中作者对数据治理的全流程做了一个介绍,数据治理流程是「从数据规划、数据采集、数据储存管理到数据应用的过程,是从无序到有序的过程,也是标准化流程的构建过程」。在公司中,数据分析师常常打交道的是:数据埋点和数据应用,当然也可以对数仓小伙伴就报表规划提出具体需求。
02
数据分析的三大思维
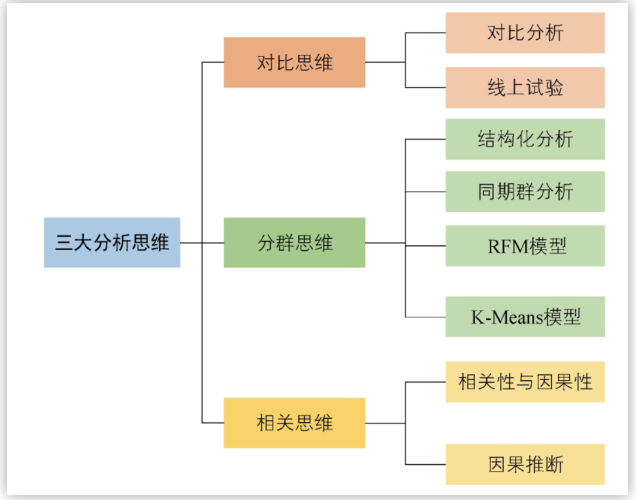
第三章作者总结了数据分析的三大基本思维:对比思维,分群思维和相关思维。
在我看来,其中「对比思维」无疑是最重要的,没有对比,就没有判断。好比说今天的dau是120万,这究竟是好还是不好呢?如果过去7天日均90万,无疑是好的;过去7天日均150万,又无疑是差的。我们呈现结论时往往都是要通过对比来实现的,无论是和大盘比,和其他业务比,和历史数据比,对比思维都是至关重要的,这样才能让我们提供的信息有价值。此外数据分析中常用的因果判断的方式「AB测试」也是对比思维的绝佳体现。
而「分群思维」其实某种意义上其实是一种拆解思维,无论我们分析的粒度是什么,我们都需要通过各种分析维度去拆解,就算是K-Means这类机器学习手法,也还是需要我们输入变量,相当于决定了具体拆解的维度。分群思维也是精细化用户运营的基础,通过不同的标签,用户所处的不同阶段,产品&运营可以对用户加以干涉。
「相关性与因果分析」是第三大思维,因为在分析过程中,我们总要达成某些业务目标,那么找到达成业务目标的关键行为就要仰赖相关系分析了。比如在分析用户的aha moment时,我们可能需要知道用户完成哪些关键行为是对产生业务付费是有帮助的。此处经常会借鉴一些经济学中因果推断的基本原理,这里也推荐一本好的入门书(之前一直想写后来写了一半不了了之,如果大家感兴趣后续会写一下):《原因与结果的经济学》。

我个人是相当推崇日本人写的这类入门书,非常详(luo)实(suo)对于我这种非科班选手来说非常友好,不会像很多大佬写的书上来就是一大堆公式直接把我打回姥姥家。
03
埋点!埋点!
第四章里作者介绍了主流的埋点方式,这章还是很值得不了解埋点的同学去仔细学习查漏补缺的,这样和产品经理沟通需求时就不会提出太多无厘头的需求,被别人像看傻子一样鄙视了。
首先作者介绍了埋点一般能采集到哪些信息:
「①设备的硬件信息,如设备品牌、型号、主板、CPU、屏幕分辨率等;
②软件能力,就算没有点击网页或者App、横竖屏、截屏、摇一摇等操作也会被记录下来;
③数据权限,新注册某款软件时,对于相册、通讯录、GPS等比较私密的信息一般会跳出让用户授权的页面,如果用户同意授权,那么网页或者App就能够采集到这些信息;
④用户行为,用户只要对网页或者App进行操作,行为都会被记录下来。」
这让我想到经常前脚照片存了个啥,后脚tb又给推荐了。我自己印象特别深有次线下拍了个很冷门的小火龙模型,后脚刷tb就出现在feed流了,商品销量是0,对用户隐私的保护也几乎是0了……加上我们每次都为了方便开放了相册全授权,也确实是拿隐私换便捷了。
而后作者介绍了前端埋点&后端埋点的上报原理:「前端埋点通过SDK进行数据采集,为了减少移动端的数据流量,通常对采集的数据进行压缩、暂存、打包上报。对于那些不需要实时上报的事件,通常只在Wi-Fi环境下上报,因此会出现数据上报的延迟与漏报现象。
后端埋点通过调用API(Application Programming Interface)采集信息,使用内网传输信息,基本不会因为网络原因丢失数据,所以后端传输的数据可以非常真实地反映用户行为」
在工业场景通常是前后端结合去埋点的,付费/注册等十分需要精准的重要数据通常采用后端埋点,而浏览/曝光等不需要绝对准确的数据通常采用前端。
后端还有个大大大优势是改动埋点无需发版,前端修bug基本都需要发版本……但是前端采集用户的行为更丰富,后端是不会记录比如地理位置,行为发生页面等信息的。
所以有时候需要前端传值给后端去上报,当然这种埋点比较耗费资源,开发成本较高,我们只在需要精确记录一些信息时才会用。
了解了这些再去和业务解释为啥前端会漏报就很容易了,综合原理可得,前端上报是几乎100%会出现漏报的,所以如果用来通过用户行为统计来实现活动发奖等功能,客诉几乎是躲不掉了。之前记得有过各种因为环境迁移导致埋点堆积,数据丢失等现象,明白这个原理就知道,没了的数据就像流走的水,补不回来了……
埋点设计过程中,规范性和全面性都是十分重要的,不然就会为后续数据分析造成很多麻烦,如果只是不规范还可以通过各种方式弥补,但想分析的地方分析不了就只能等下个版本上线了……
一个埋点事件的上线,需要包含以下几个环节:
确认事件和变量 → 明确事件的触发时机 → 明确事件的上报机制 → 统一表结构 → 统一字段名规范 → 明确优先级。
确认事件和变量:首先我们要明确需要监控用户的具体哪些行为,分析师还需要在埋点上线前有预设,哪些维度是后续需要量化成指标,或者是有分析价值的。
比如说如果我们要看「商品详情页的浏览」事件,除了一些常规信息(比如平台,app版本等等)和最基本的内容信息,比如用户从哪个模块来,又访问了什么内容。我可能还会关心用户具体浏览到页面的什么位置促成了后续转化,那么浏览深度也是我们需要关心的。此外为了方便的计算详情页转化率,我们可能也想要知道用户在浏览前是否已经购买过该商品。
明确事件的触发时机:这个是重要又容易缺失对应测试的。时机不准确造成的问题包括但不限于:时机没选对,该曝不曝,不该曝偏要曝光。我在工作中就遇到过这样的例子,某些不该被记曝光的页面在用户未进入该页面的情况下也记录曝光,不但影响数据的准确性,还影响了某些用户权益的获得…
明确事件的上报机制:这里其实就是明确咱们这个事件是选择前端埋点还是后端埋点,走实时上报还是异步上报。
统一表结构:这一块则偏向底层建设的原始规范,后期再去变动成本是相当高的。
统一字段名规范:这个需要额外多说两句,在一些发展较久的公司,埋点成型较早,可能我们面对实际埋点时已经发现已经是粪山了,没有办法,后续能规范还是先规范起来。比如说,付费金额,不能在a事件里是amount,在b事件里是pay_amount,在c事件里是money…
金额也要采取固定的统计单位,不能这里是到分,那里又到元(之前还有平台类型一会是ios一会是Ios还可以是IOS的例子,属性值如果是文字类,最好能做到枚举清楚),不然在数据统计时都会造成各式各样五花八门的问题。
明确优先级:这块主要是帮助产品和开发同学了解哪些事件和维度最为重要,没有分析就没法干活的,毕竟有时候需求时间紧任务重,开发同学未必能满足全部的埋点需求,优先满足重点需求就十分有必要了。
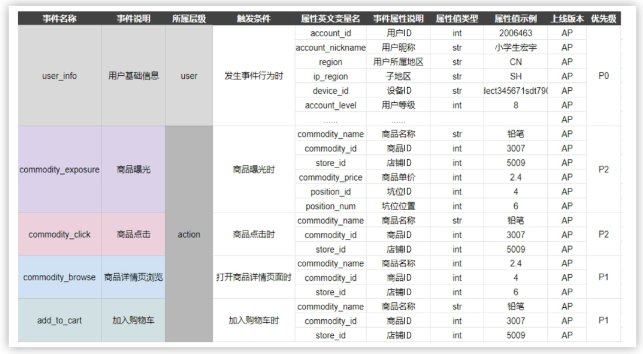
作者在这一章也给出了埋点文档的样例,可以学习一下。
说完埋点这本书进度差不多过半了,字数也已逾3000大关,自古长文被嫌弃,那么下一篇再继续聊后半本书。
咱们下篇再见咯。




