







本文来自微信公众号 “ 零号产品er ”,作者: zmL,纷传经授权发布。
01
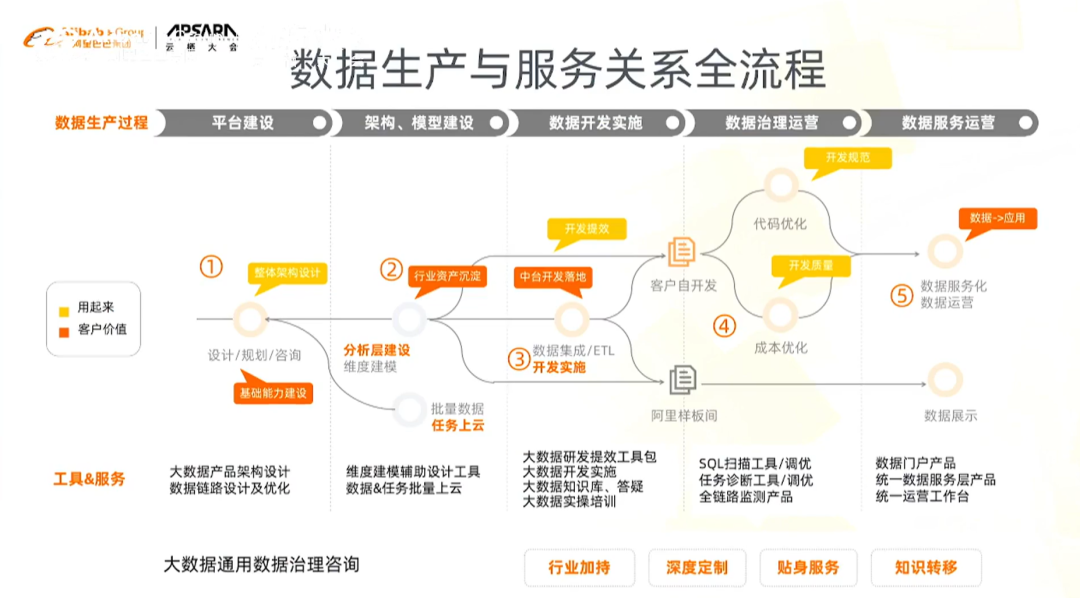
基于DataWorks的数据治理全过程
存在三类客户:
第一类客户是已有自己的大数据平台,希望迁移和使用阿里DataWorks的大数据平台。该类客户主要关注数仓分层规划、数据建模、大数据生产链路设计等方面
第二类客户是已经使用了DW,关注重点是大数据链路是否稳定运行、整条链路上是否还有一些问题,如何溯源解决,以更好的支撑业务
第三类客户是重点关注在数据价值,其大数据平台比较成熟,在平台上有很多表和任务,这些表和任务是否产生了价值,如何衡量和体现,如何把计算资源用在刀刃上
02
元数据驱动的数据生产智能
在openAPI和开放数据上实现元数据采集和分析功能,重点关注数据治理过程的三个方面:建模、监控和优化,从插件角度看如何利用元数据、分析元数据,然后持续的产生新的元数据,最终形成基于元数据驱动的全链路数据治理过程。
1)元数据驱动的数据治理
元数据驱动的数据治理可作用环节在于:数据生产全过程,关键节点包括:数仓规划设计、数据探查上云、数据模型设计、治理监控、运营优化
在整个过程中每个环节都会涉及不同的产品、组件,产生不同技术元数据和业务元数据(数据治理过程中对业务的梳理、数仓分层规划、对标准的展示等所形成的业务元数据)
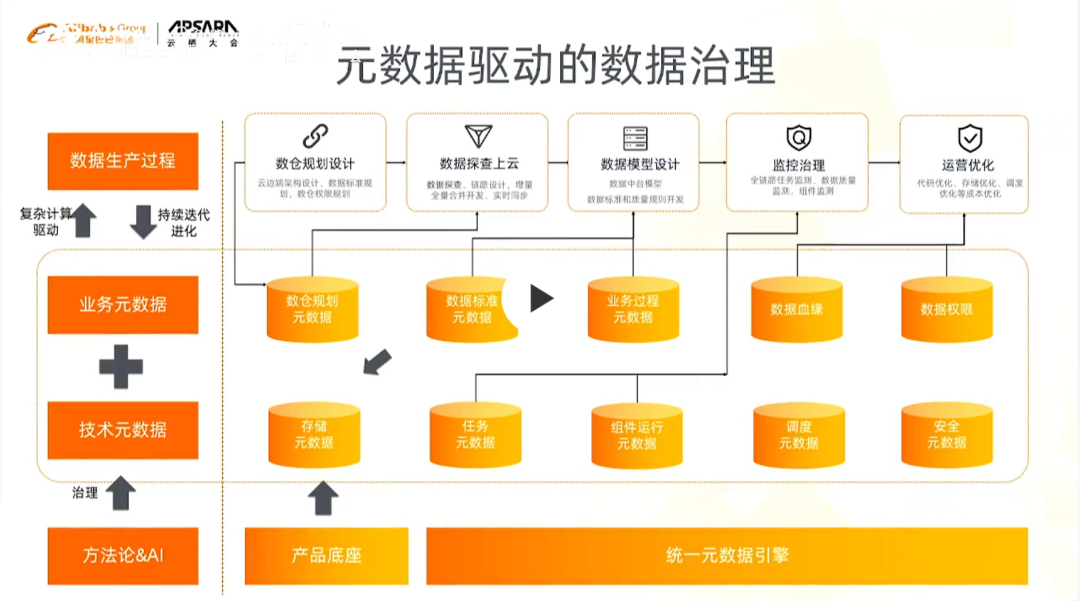
在方法论落地过程中,会有很多问题,比如如果只聚焦某一个环节,相对来说,数据本身的来源和生产,也还局限于在某一个环节中。而我们希望在数据生产消费全过程中,构造一个以元数据的生长、聚合、驱动产生的数据治理过程,基于DataWorks完成数据治理流程。
举例来说,在数仓数据模型设计时,会考虑之前做的分层规划、对元数据的探查、对业务系统的分析,整个过程中产生的分层数据是否为后期做监测和优化提供数据支持。
2)元数据应用升级
元数据应用存在的主要问题:时空隔离:
空间隔离:在数据开发、治理过程中,元数据散落在不同的组件、系统、平台中
时间隔离:在整个治理环节,不同的元数据起到不同的支撑作用,不仅仅是单环节的
元数据应用价值:
我们不仅是要把所有的元数据收集起来,而且是要建立不同节点之间的关联关系,从时间和空间角度将有价值的元数据以一种最佳的形式组织起来,最终形成全链路数据治理大图
这张大图为数据治理的每个环节提供服务
大数据平台的全景展示
元数据智能:提供数据治理的AI能力
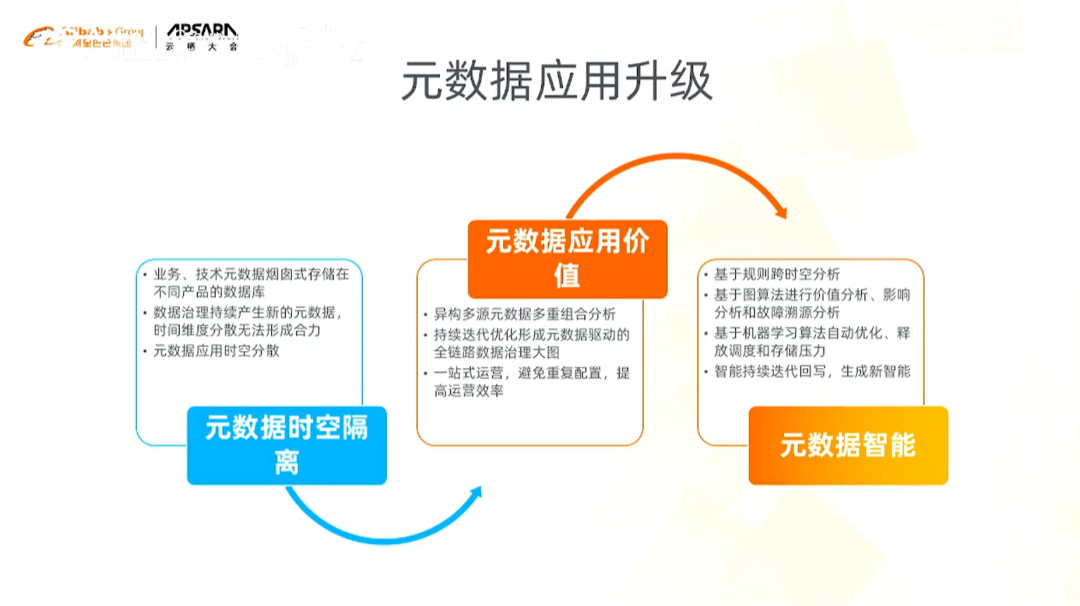
目前元数据驱动的数据生产智能主要聚焦于智能建模、智能监控、智能优化三个方面

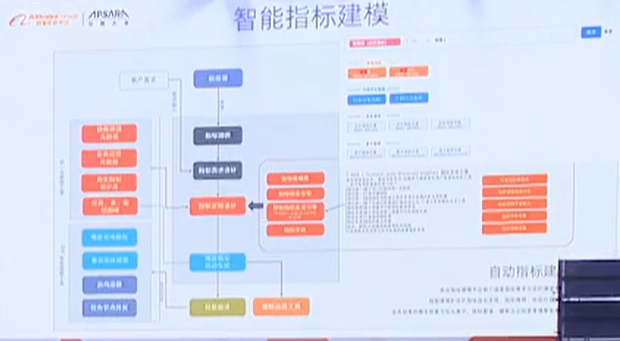
3)智能建模
建模过程:梳理业务流程-->找到派生指标--->找到派生指标和原子指标之间的关联关系与计算逻辑
真正的复杂点在于:对大量的原子指标(是基于某一业务过程创建的,用于明确业务的统计口径和计算逻辑。原子指标是指标体系的基础,其他指标,比如派生指标,都是在原子指标基础上加工而来)进行溯源:数据源中可能有成千上万张表和很多字段,并且很多字段的意义是重复的。所以表面看数仓建模的方法论非常的标准,但是在真正实施过程中能够容易事倍功半,原因在于
数据本身存在二义性
数据需求不断变更
因此,从指标的分析到数仓分层的形成整个过程中,需要大量人工的参与,会依赖于业务梳理的元数据,探查源端数据库中的表、数据字典和物理模型等这些元数据。基于这些元数据生成指标树以及各行各业积累的方法论自动生成数仓分层,这个分层是一个逻辑模型,结合DataWorks的API和元数据的形式回写到平台上,最终形成元数据的输入和元数据的输出(通过元数据的输入输出实现智能指标建模)。
作为一个引擎,自身有一定的数据存储和固化,他除了能做一些指标上的推荐、探索、智能建模之外,也会把指标的元数据继续提供给后期的数据治理,进行数据治理的支持。
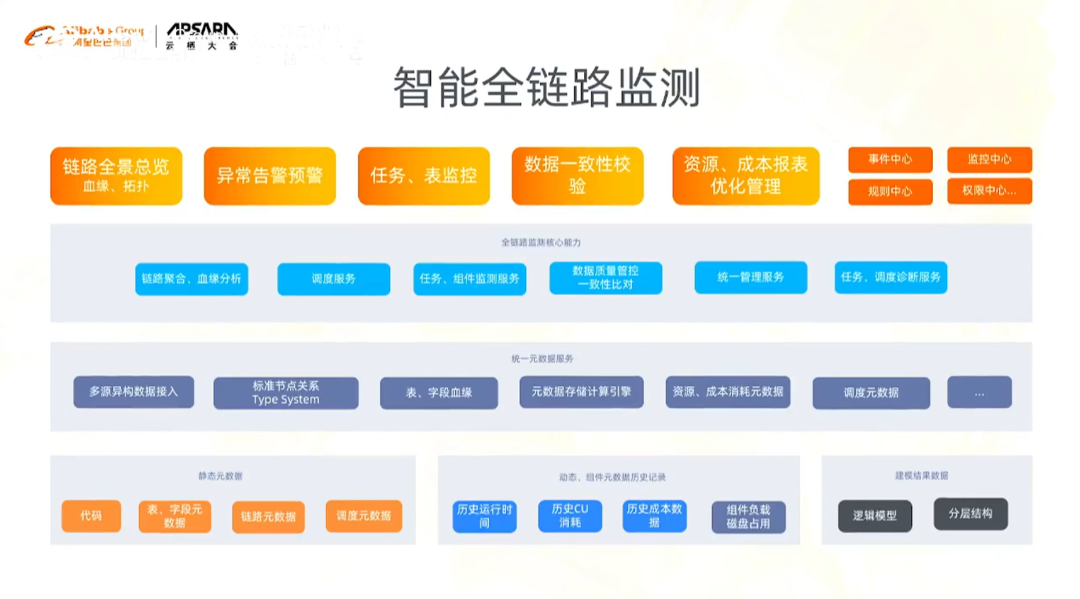
4)智能全链路监测
有很多数据链路和分析过程是散落在其他引擎/平台/产品中。
数据从源端接进来,经过实时开发、离线开发,经过三层数仓,通过数据服务最终被业务系统使用。在这个过程中,当一个API或服务出现问题时,怎么能快速定义到问题是出现在哪里,是出现在开发环节,还是在源端,不管哪里,这都是一个非常长的链路。通常情况下,我们会在不同的产品中一层一层的溯源。
链路监测需要解决什么问题?
跨产品、跨空间的数据链路的聚合
实现源端的影响力分析,以及目标端出现故障之后的溯源
全链路数据一致性、数据监测、以及为后期的运营优化提供支持
在这其中,技术视角的元数据主要来源于DataWorks和计算引擎。
DataWorks有自己的调度元数据、代码自身、实例的元数据
有一些元数据是散落在计算引擎中的,比如CU消耗的数据、每个任务运行状态、消耗的时间等
基于这个,我们才能找到计算引擎和DataWorks中调度元数据的聚合,为后期的优化提供一些支持
同时,数仓建模过程中所维护的指标树,可以为链路监测提供业务视角的元数据。
通过大数据底层DataWorks能够拿到所有数据的运行状态、物理表、节点、SQL等,但这些都是技术视角的元数据
我们希望看到开发的数据服务或应用,他们之间是不是有些问题。
所以将业务视角的元数据和建模时的元数据进行关联起来,统一进行分析,直接提供的就是业务视角的链路监测能力
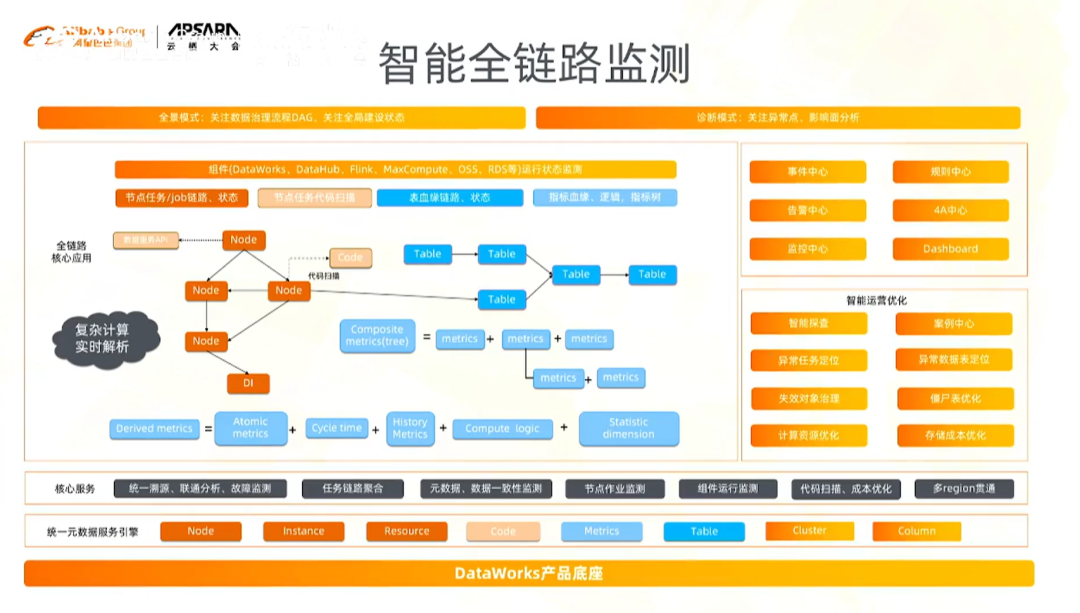
下图中,有很多元数据类型,初窥一下我们对元数据统一和聚合的设计思路。
图中的node节点,可能是
第一类:抽象的代码、节点任务等
第二类:这些节点关联的表、字段
第三类:数据治理过程中沉淀的业务元数据:指标树以及原子指标和派生指标之间的逻辑关系
这些会形成自己的类型系统,我们将每一种类型标准化(在这个过程中,我们可能不会遇到太多种类型的元数据)。
为什么要这样做呢?:通过将他们建立关联关系,就可以从任意节点出发,寻找问题。
假设一张表今天数据量突然猛增或为0,我们就要看这张表影响了哪些业务,或者找到开发这张表的任务节点,从任意节点出发,通过连通图的算法或者机器学习算法找到最佳的聚合关系和影响范围。
再比如,一张表,今天的数据为0,我们可以不停地向上溯源,找到最前端的那个数据集成任务、找到中间的实时计算的任务等。每一种任务都有自己的运行实例、实例的状态,这些信息(这些信息就是表(数据实体)的技术元数据)就会跟元数据信息产生关联,这样我们就能很快的定位到任务本身对表的影响。此外也可以找到与表本身相关联的业务属性(这些信息就是表(数据实体)的业务元数据),业务属性就体现在指标的建设过程。
5)智能优化
如何减少让大数据资源消耗在无意义的任务/表上,让大数据平台产生更大的价值,提出两点:
如何基于元数据对代码进行扫描和优化
如何基于元数据对存储资源、计算资源进行优化
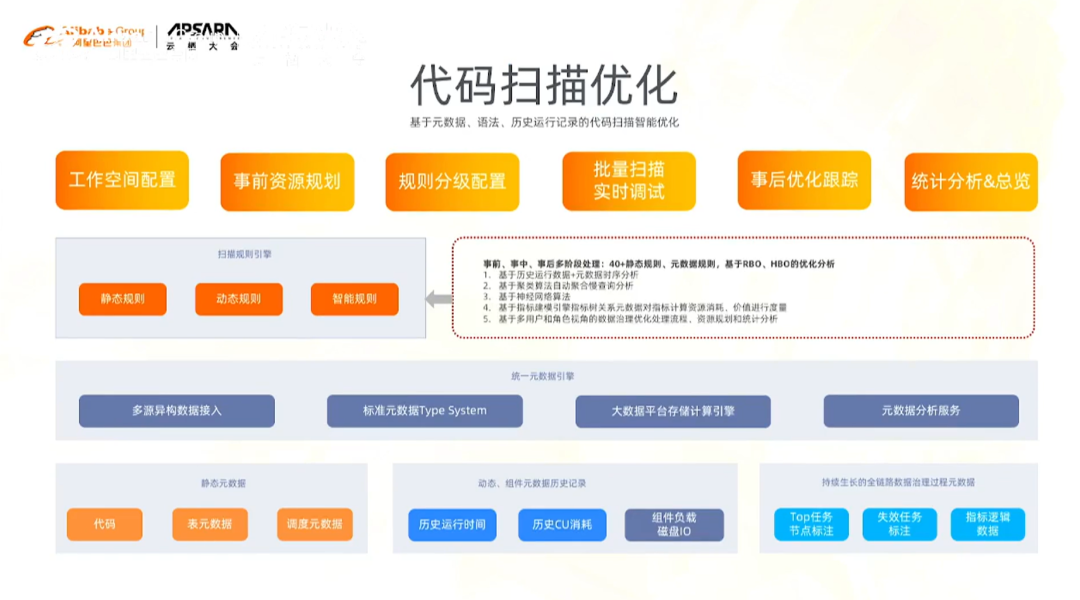
①代码扫描优化
基于类似“健康分”的判断逻辑找到哪些代码是不符合规范的
代码扫描主要依赖的元数据是SQL(代码本身)和SQL中包含的表在底层存储空间上值的分布
因为光分析代码是不够的,写SQL过程中会想当然的join一些表,这些表非常大,容易产生“数据偏执”,因此在运行任务时,表面上看很正常,但是实际上一些任务超长运行,或者不运行,其他任务都等着这个任务的完成
所以我们把DataWorks中的代码元数据、在计算引擎中运行的CU消耗的数据、每个任务运行状态、消耗的时间等数据,以及DataWorks的元数据和底层Maxcompute两个instance之间的关系,建立大的关联关系,基于这三方元数据做统一的分析。
在其中,我们提供了40+多种静态规则/动态规则通过元数据分析来进行代码优化分析。
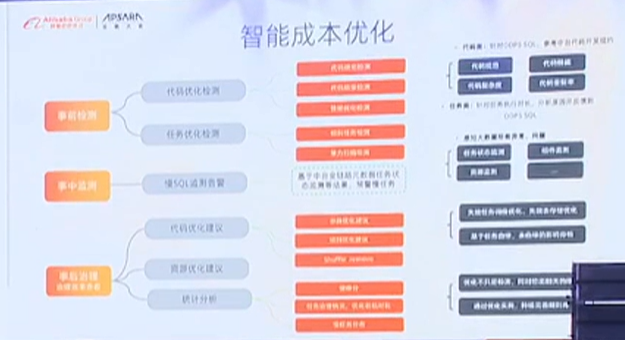
②智能成本优化
成本优化包括存储资源优化和计算资源优化。
存在的问题是:
任务很多、大宽表(很宽很宽)--->价值很难说明白
通过字段的血缘关系、调度关系、以及字段与指标之间的关系形成统一的元数据网络,实现提供智能优化的能力
重点提供失效任务的优化、调度优化--->减少对计算资源的消耗
找到不常用的字段、表,进行快速的释放
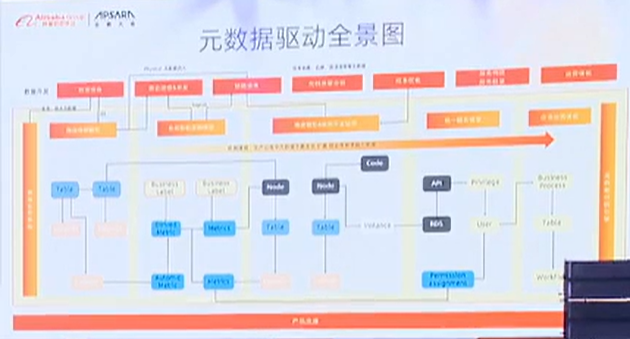
6)统一的元数据管理
下图为元数据管理和聚合形成的元数据驱动全景图,从左到右仍然是数据治理的全链路流程,在每次数据治理过程中会产生新的元数据,也会采集一些元数据,这些元数据最终以图的形式存储在计算引擎中(知识图谱)。
从左到右,一开始是采集到的物理表的元数据,
到中间建模的过程中,会有一些业务元数据,
再到开发的过程中会有一些平台的元数据,
这些元数据会持续的生长和迭代,形成统一的元数据管理。--》交付提效
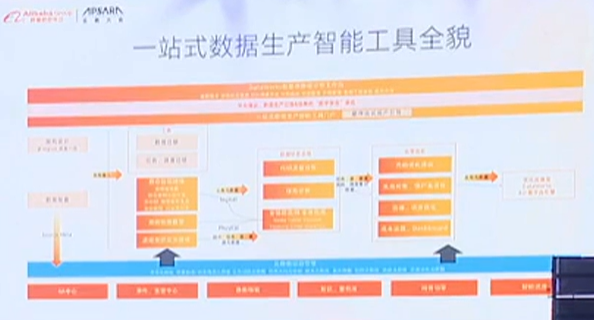
最终基于这几个阶段的开发,元数据的整理,最终形成一站式数据生产智能工具全貌。
复杂架构下的大数据平台,大家始终都会面临着一个问题:
我的数据是怎么流转的,任务是运行的,这么多组件是怎么协同的。
另外,从业务的视角上,怎么在大数据建设过程中体现“数据孪生”这样的概念,怎么给出一个基于业务视角的数据全链路展示。
我们从数据治理全流程中(从建模、开发到运营优化,持续迭代)会形成持续的元数据流,除了丰富我们元数据引擎外,也会运用算法持续优化元数据驱动的数据治理过程。
数据治理本身产生的元数据也会带来一些价值:在后期,会对之前的设计做一些调整和优化,如果没有持续跟进的线上化系统的话,也会丢失一部分细节,最终很难保证我们的设计和落到大数据平台里面的表设计、任务等一致性。
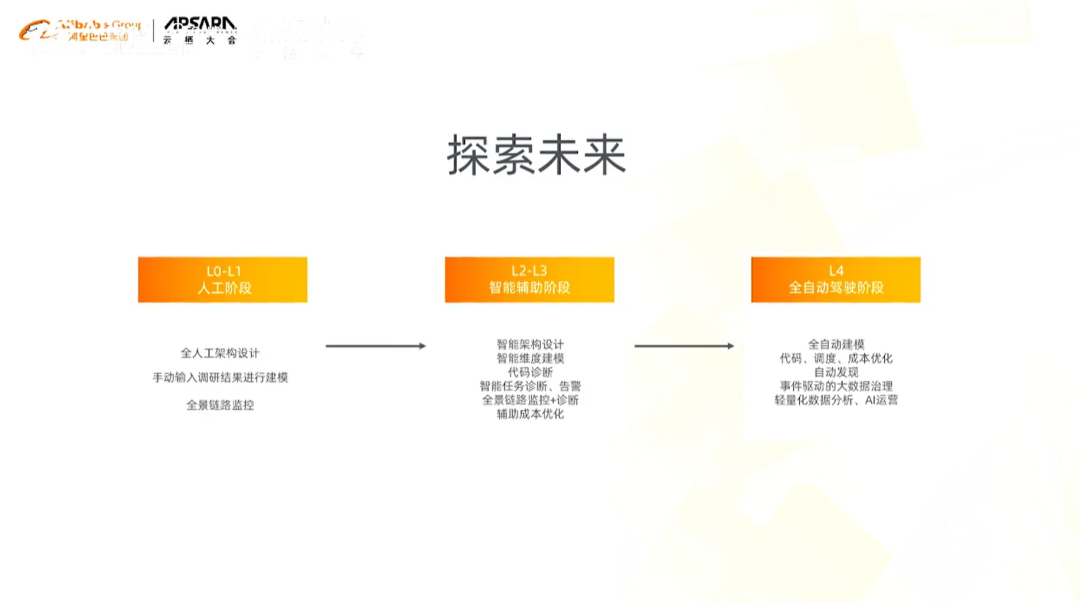
元数据驱动的数据治理是一个长期的任务,第一阶段是人工阶段,第二阶段是智能辅助阶段,第三阶段是全自动驾驶阶段。
完整版视频链接(01:04:30--01:33:26 ):
https://yunqi.aliyun.com/2021/agenda/session102?spm=5176.25018482.J_5684470790.19.5abd49edic7WY0




