








本文来自微信公众号 “程序员贺同学”,作者:herongwei,纷传经授权发布。
大家好,我是贺同学。
一直以来密切关注 ChatGPT 的趋势,最近相关的话题可谓是热度不减,虽然从事互联网行业,但一直对 LLM 相关领域关注较少。
最近的 ChatGPT 的火热,让我对 LLM 相关开源社区也关注了起来,相关的开源社区,也涌现了很多优秀的工作,吸引了很多人的关注。
其中,大家比较关注的是 Stanford 基于 LLaMA 的 Alpaca 和随后出现的 LoRA 版本 Alpaca-LoRA。
原因很简单,便宜。
https://github.com/tloen/alpaca-lora
Alpaca 宣称只需要 600$ 不到的成本(包括创建数据集),便可以让 LLaMA 7B 达到近似 text-davinci-003 的效果。
而 Alpaca-LoRA 则在此基础上,让我们能够以一块消费级显卡,在几小时内完成 7B 模型的 fine-turning。
下面是开源社区成员分享的可以跑通的硬件规格及所需时间:
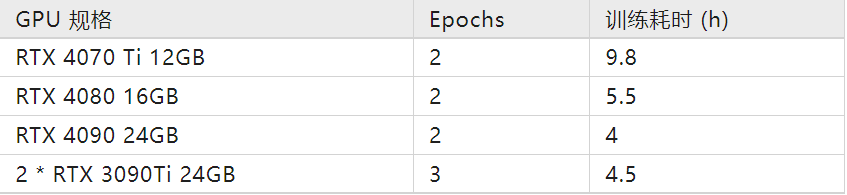
根据大家分享的信息,fine-tune 7B 模型仅需要 8-10 GB vram。因此我们很有可能可以在云服务器上完成所需要的 fine-tune!
另外,自 ChatGPT 惊艳问世后,大模型部署的话题一直高热不退,但是这里面存在两个显著的问题:
一方面 ChatGPT 只有蛛丝马迹的论文,没有开源代码;另一方面 ChatGPT 官方公布的训练硬件配置,至少数千块 80G A100 的高昂算力成本。
以上两点,无论哪一个,对于很多想尝试动手搭建的普通人或者非计算机行业的朋友们,都是不小的挑战,导致很多个人用户无法上手。
那么,有个想法就在脑子里酝酿了,我们能不能自己动手训练一个ChatGPT出来呢?说干就干!

和小伙伴一起,花了一个周末,经过不断尝试踩坑,终于在云服务器上调通了!
基于最新的 Stanford 发布的基于 LLaMA的Alpaca-LoRA,70 亿参数规模,只需要 A5000,3090 等最低 24G 显存的消费级的单卡 GPU 就可以训练。
而且还可以更新语料库进行训练。
这一步,无疑大大降低了大语言模型的上手入门的门槛。
我一直坚信,分享即学习,好知识值得分享和传播,话不多说,我们接下来开始进行逐步讲解。
01
搭建云 GPU 服务器环境
云 GPU 服务器,这里有两个厂商推荐(没有广告,纯粹推荐)
DBChina https://www.haibaogpu.com/wholeVirtual?type=gpu
阿某云的 GPU 服务器
根据个人情况租用或者购买,如果自己有更牛的硬件配置,那就当我没说,可以自己本地就 run 起来!
推荐跑模型的话,DBChina 平台推荐按小时去租一个单卡的机器,具体操作大家可以网上搜索。
其实看了下,最便宜的日租金大概算下来几十块钱,性价比还是可以的,所以想亲身体验的朋友,可以尝试一下。
笔者买的是阿某云 GPU服务器,这里推荐大家可以按量购买,参考下面的规格来买,一个 V100的 GPU,内存 >= 24G 的。
这里我在厂商买的时候,最小的机器配置只有 92GB 的,所以就买了这个。
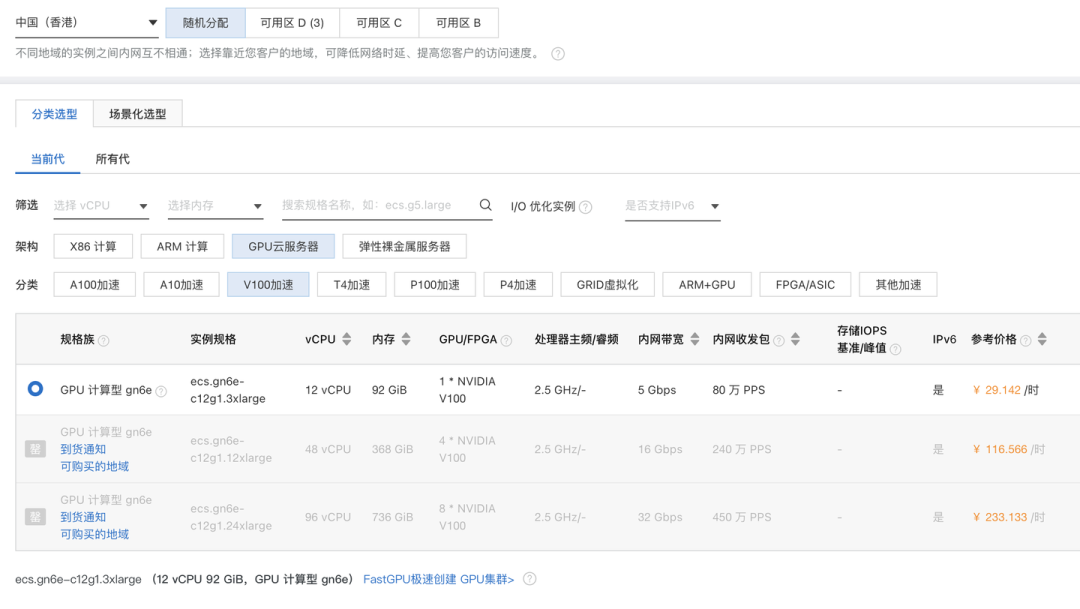
踩坑一:推荐买香港的或者国外的机器,下载开源仓库的时候需要访问 GitHub 。
国内的机器大家懂的,会不太稳定,当切换了香港的机器之后,你就会立体验到那种丝滑的感觉!
02
配置机器
拿到机器后,登录进去,需要配置一下开发的环境,配置 Git ,命令:yum install git 安装 conda 环境,下载一个 miniconda 就好,非常快
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
其他版本下载地址:https://www.anaconda.com/products/distribution#Downloads
安装好之后,执行安装脚本,bash Miniconda3-latest-Linux-x86_64.sh 即可,一路 yes 。
接下来,需要下载 Alpaca-LoRA 项目代码,下载前,我们需要配置本地的 Git 的环境:
1. 设置的用户名和邮箱
2. 生成SSH Key密钥
3. 获取SSH Key密钥

具体步骤可以参考网上文章,这里就不详细说了。
那么机器配置好了 Git 环境之后,我们就可以正常下载代码了。
下载 Alpaca-LoRA 项目代码 终端输入命令:

创建对应的虚拟环境,并安装项目所需的依赖


接下来,我们下载项目训练的数据集
wget https://github.com/LC1332/Chinese-alpaca-lora/blob/main/data/trans_chinese_alpaca_data.json(有坑)
踩坑二:这里有个坑,其他教程这里都说直接下载这个文件,当初我也是这个文件下载的,美滋滋的下载完开始跑的时候,发现报错了!
报错原因是文件格式不对!!
导致模型启动失败!
其实,上面这个文件格式不正确,至少在我今天跑的时候有问题。
正确做法是执行这个命令:git clone https://github.com/LC1332/Chinese-alpaca-lora.git
克隆项目之后,切换到 data 目录下,可以看到 trans_chinese_alpaca_data.json 数据集文件的位置,把它 cp 一份,拷贝到 alpaca-lora 目录下。
所以说,注意下载完后,要进行检查,下载好的数据集文件内容格式是如下这样的 JSON 格式,这个数据集当然也可以更换成自己的 :

03
开始训练模型
训练
进入 alpaca-lora 项目目录,执行命令
踩坑三:经验丰富的工程师,都会知道,一个命令如果需要长时间执行的话,最保险的做法就是把它挂到后台运行。
这样及时你一不小心把前台关闭了,程序仍然老老实实的继续默默运行着。(老程序员也有大意失荆州的时候?)
nohup xxx & 是把一个命令挂到服务器的后台运行!
单卡选手很简单,可以直接执行:

双卡选手相对比较麻烦,需要加额外的参数执行:

如果你的内存 24GB 左右,需要额外配置 micro_batch_size 避免 OOM。(不像我一样第一次跑到 90% 结果 OOM,然后只能含泪重跑?)
--micro_batch_size 2
推荐的其他额外参数:
--num_epochs 2
执行完上面的命令,服务器终端会下载一堆玩意,耐心等一会
可以看到,上面的输出参数
如果发生如下报错:AttributeError:
/root/anaconda3/envs/alpaca/lib/python3.9/site-packages/bitsandbytes/libbitsandbytes_cpu.so: undefined symbol:
cget_col_row_stats
需要进入/root/anaconda3/envs/alpaca/lib/python3.9/site-
packages/bitsandbytes 文件夹中 执行如下命令:cp libbitsandbytes_cuda117.so libbitsandbytes_cpu.so 解决依赖冲突问题
04
训练观察
顺利执行成功后,会进入训练页面,训练的过程比较稳定,推荐在用 nvitop 命令,查看显存和显卡的用量:
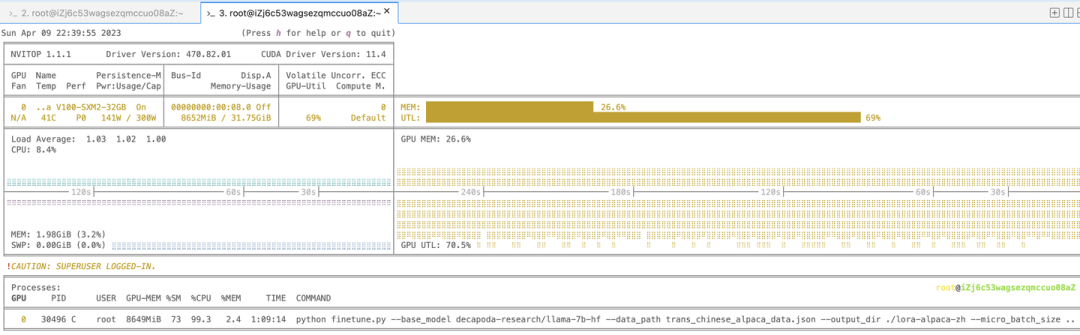
在观察的时候,发现 32G的显存,模型刚跑的时候不到 8G,可能只是刚开始,毕竟有将近 70 亿参数。
理论上,这样看更低的显存机器应该也可以cover。
看日志,怎么着也得10h起步的训练时长了,等明天有空看效果吧。
05
后记
上面的涉及的一些参数含义可参考,这里不具体阐述
https://paddlex.readthedocs.io/zh_CN/release-1.3/appendix/parameters.html
具体的训练效果,等明天应该就差不多出来。
这篇文章带大家从头到尾实战了一把 ChatGPT的训练过程,我们可以从整个过程中看到,语言模型迭代的本质,其实还是海量的语料数据的训练。
从历史回到现在,ChatGPT 的背后是一个叫做语言模型的一个数学模型在发挥作用。
换句话说,ChatGPT 的背后是一个数学模型。只
不过在今天,这项技术显得很强大的原因主要是三个:
第一,它用到的计算量很大;
第二,它的数据量很大;
第三,今天训练语言模型的方法比以前要好很多。
最近读到一篇吴军老师的访谈文章,里面提到 ChatGPT 对我们到底有什么影响?
吴军老师的回答我觉得一语中的,这里摘抄一下
今天互联网上90%的内容都属于这一类——不提供更多的新信息,也不是原创内容,也不是自己的感悟,无非是东抄抄,西凑凑。
目前,抖音、快手这类短视频,我觉得99%的内容都属于这一类,没有营养,你读完以后可能觉得挺有意思,但实际上你在上面读了再多,其实对你没有任何帮助。
如果说ChatGPT真的威胁到了谁,我觉得威胁到的就是这一类人的工作。
所以这项技术会对这一批人会有影响。
那么,什么人不会受到影响?
就是内容创造的人不会受影响。
所以我认为,从历史上看ChatGPT其实不算是一次技术革命,它影响到的都是那个比较懒的人,懒得动脑筋,创造新东西的人。
真正探索人类知识奥秘的人,是不会被取代的。
与你共勉 !




