








本文来自微信公众号 “马丁的面包屑”,作者:做产品的马丁,纷传经授权发布。
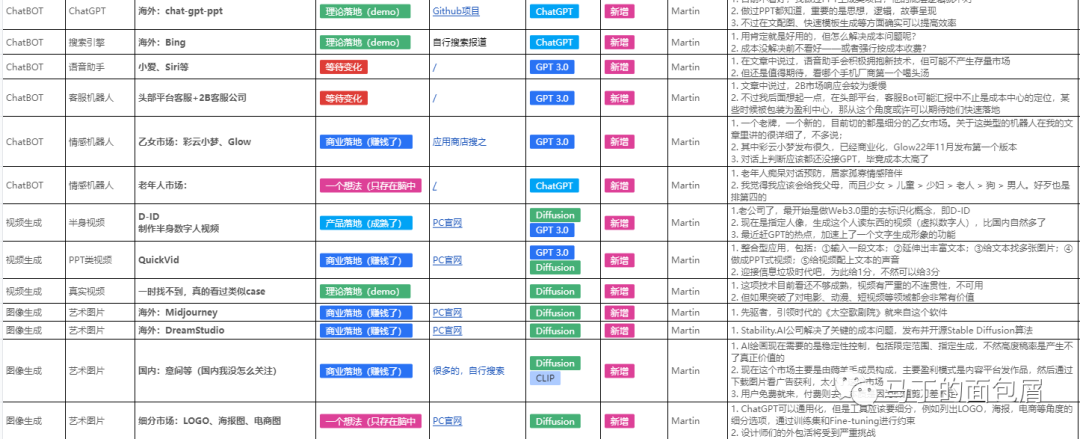
我整理了40+GPT方向&Diffusion方向目前听到、看到、体验到的落地项目及可能方向,每个方向都包含有基本的商业化及技术可行性分析。
就是下图这个,后续会持续增加并更新信息
那么为什么我要做这个东西,并大言不馋地说是“开源”呢?难道把一个Excel分享一下就叫开源了吗?
接下来耽误您三分钟时间听听我的前因后果。除了这个商业库以外,我希望中间的思考对您也能产生价值。
01
为什么要做这个东西?
相信很多人认识我是从这两篇万字长文开始的,即:
万字长文:AI产品经理视角的ChatGPT全解析
深度思考:AIGC这波技术狂潮能否商业化落地?(内含思维导图)
这两篇文章一共用了我一周的时间,但是写完后我就发现,我其中的信息已经开始过时了。
甚至最极端的情况,我在改完错别字,准备发的时候,突然就发现某个技术瓶颈已经消失了!
这波浪潮来得如此汹涌猛烈,以至于我陷入了信息焦虑状态,为此甚至停下了计划中的后续产出。
这种焦虑主要来自两个方面:
第一,信息急速涌现:
1. 迅猛,快速的创意涌现,每天都会成堆的报道冒出来GPT又能做这个,还能做这个。
2. 技术处在进一步爆炸的前夜,今天的缺点,可能明天就已经被解决。
第二,信息熵极低:
1. 鹦鹉学舌式的重复叙事,同样的内容冠以不同的标题在互联网上到处分发
2. 部分信息一知半解,甚至带来错误的输入
我就像一只田里的猹,被互联网的瓜轮番轰炸。为此我决定暂停信息获取,先重构我的知识体系以及知识处理模式。
以上,就是我为什么要做这个东西的原因。——我需要一套高效率,可扩展的,可拔插的系统,应对这个时代。
并且,补充一点:我认为,在内容创作的“社会必要劳动时间”革命前夜,内容爆炸时代来临之前,做好信息过滤机制是非常重要的一件事情。
这不止对我,对各位读者我认为也非常重要。

02
那么为什么叫开源呢?
我在整理商业库的时候,发现一个有趣的东西——GPT-J,目前开源的大语言模型之一,对标GPT-3。
那么他是怎么来的呢?我找到的信息原文是:“为了打破 OpenAI 和微软对自然语言处理 AI 模型的垄断。
Connor Leahy、Leo Gao 和 Sid Black 创立了 EleutherAI,旨在通过开源模型,打破垄断”。
太酷了哈哈!我也想做一些酷一点的事情!但可惜我不是程序员,敲不了代码,体验不了这种极客精神的愉悦。
不过,恰好我的商业项目库存在一些可改进空间:
一个人的信息获取是片面、有限的。
多人协作会比单人努力更激发热情。
读者在获取的同时进行输出,也能够加深记忆。
nice,搞起来。做不了开源coding项目,我可以做一个开源知识项目。
那么这个商业知识库具体怎么用呢?
我会提供基础的起步信息,填充40+以上的商业项目及相关分析。
读者可在Sheet【商业库-只读】中进行阅读,但不可编辑。
同时开辟Sheet【发言区】,读者在此提交商业库不存在的信息。
我将定期将【发言区】中的信息过滤、整理后,填充到【商业库-只读】中,并标识此条信息来源人。
最后,当发言区提交的有效信息>40条(超过我的原始信息数目),我将开放【商业库-只读】的导出、复制权限——因为到了这个底部,他已经不是我的个人智慧,而是群体智慧产物。
p.s 通过【发言区】而非读者私信的原因是:我希望大家互相碰撞观点+避免信息不互通造成的重复提交。
03
最后,为啥只是个Execel
在产品理念中,有个东西叫MVP,即最小可用产品。
就是当你想做一个长城贴瓷砖项目时,别起手就10亿投资。
花个10W,找个导演拍个视频投放一下,看看全国人民买不买这个创意的单。而10亿VS10W,这就是MVP的魅力。
而这个开源知识库听起来很酷,但实际上存在很多问题,充满了不确定性:
1.读者真的会提供输入吗?他的动力是什么?
2. Excel分享导致的完全开放,没有门槛的准入机制,是否会让发言区良莠不齐呢?
3. 知识的爆炸是持续的,以至于需要一个常态化运作的知识库吗?或许只是一波媒体狂欢而已呢?
所以,用一个我本就会梳理的EXCEL,来验证项目可行性,并获取对用户的认知,就是再好不过的方法了。
好嘞,耽搁您看了这么多我的废话,再次表示歉意。




